Variational Autoencoder for MNIST Digits
Generative modeling of handwritten digits using a variational autoencoder (VAE) combining an LSTM encoder and CNN decoder
✨ Motivation
This project implements a Variational Autoencoder (VAE) to learn latent representations of MNIST digits. Unlike conventional autoencoders, VAEs model latent distributions, enabling sampling of new images. The architecture combines an LSTM encoder, which processes images as sequences, and a CNN decoder, which reconstructs outputs.
⚙️ Implementation Highlights
- Encoder: Single-layer LSTM treating each 28×28 image as a sequence of 28 rows. Hidden size: 64 units.
- Latent Variables: Mean and variance outputs for reparameterization and sampling latent vector z.
- Decoder: Transposed convolutional layers and dense layers in multiple configurations.
- Loss Function: Binary cross-entropy plus KL divergence.
- Training: 50 epochs with Adam optimizer (learning rates between 0.0005–0.001).
🛠️ Workflow
- Data Preparation: MNIST images normalized to [0,1].
- Model Construction: LSTM encoder and CNN decoder defined in TensorFlow.
- Training: Mini-batch gradient descent, batch size 100.
- Evaluation: Reconstruction of test images, generation from random latent vectors, convergence analysis.
🧪 Results and Visualizations
Seven configurations were tested to improve reconstruction accuracy and sample diversity.
🔹 Baseline Configuration
Setup: 3 transposed convolution layers, no dropout, learning rate 0.0005.
Observations:
- Reconstruction loss decreased and stabilized by epoch 20.
- KL divergence increased gradually.
- Reconstructions were clear.
- Generated samples often lacked detail or were blank.
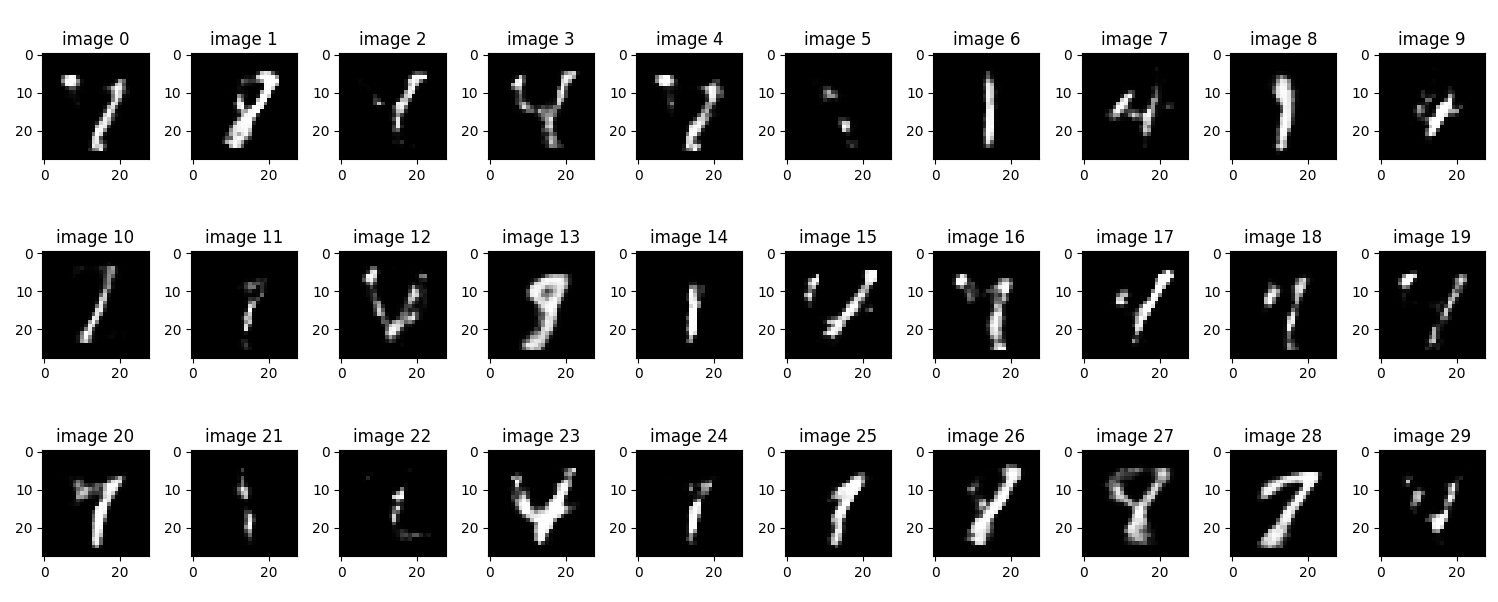
Reconstructions – Baseline Model
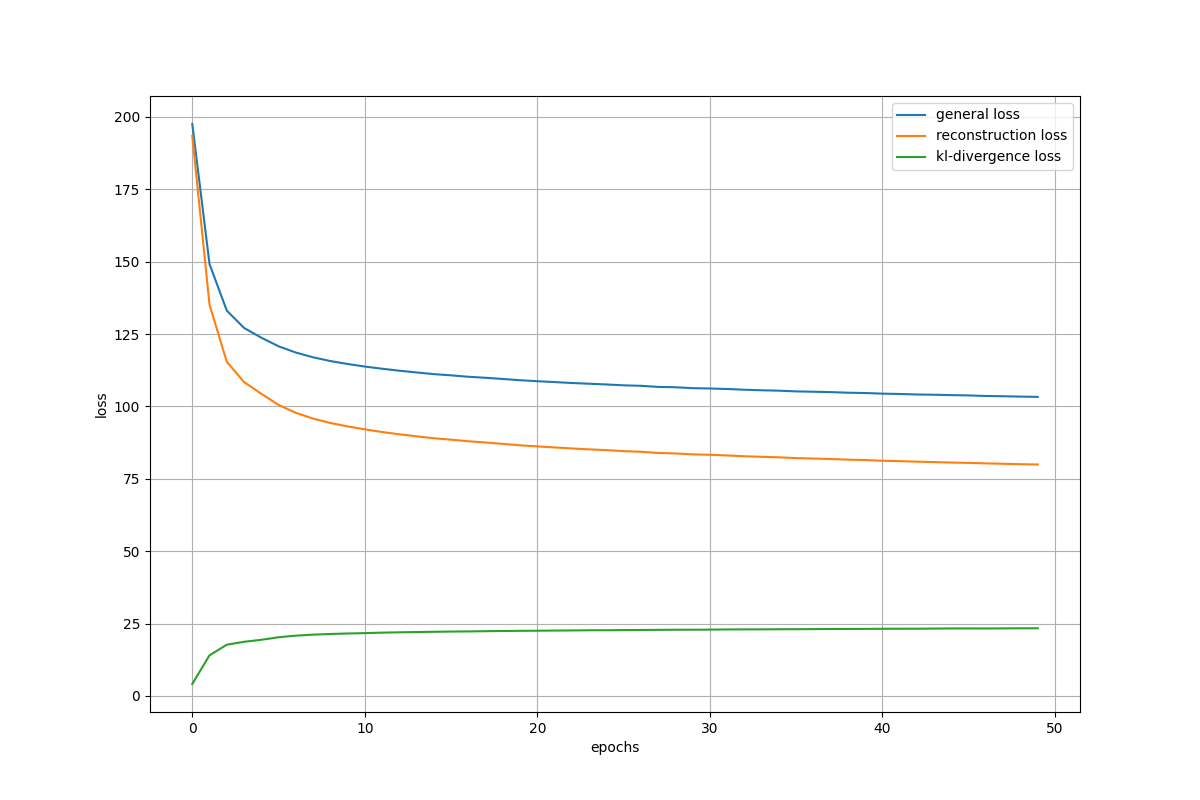
Training Loss – Baseline Model
🔹 Deeper Decoder
Setup: Additional transposed convolution and dense layers to increase model capacity.
Observations:
- Reconstructions became sharper.
- Generated digits remained repetitive.
- KL divergence slightly higher.
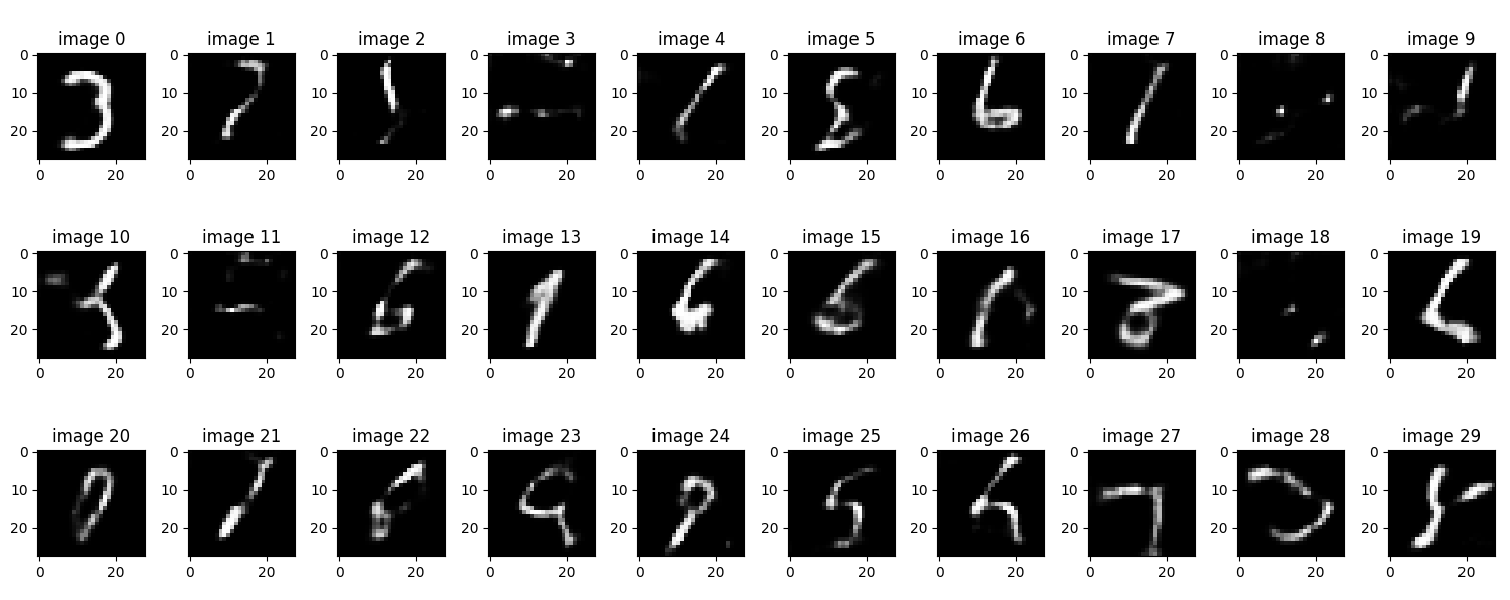
Reconstructions – Deeper Decoder
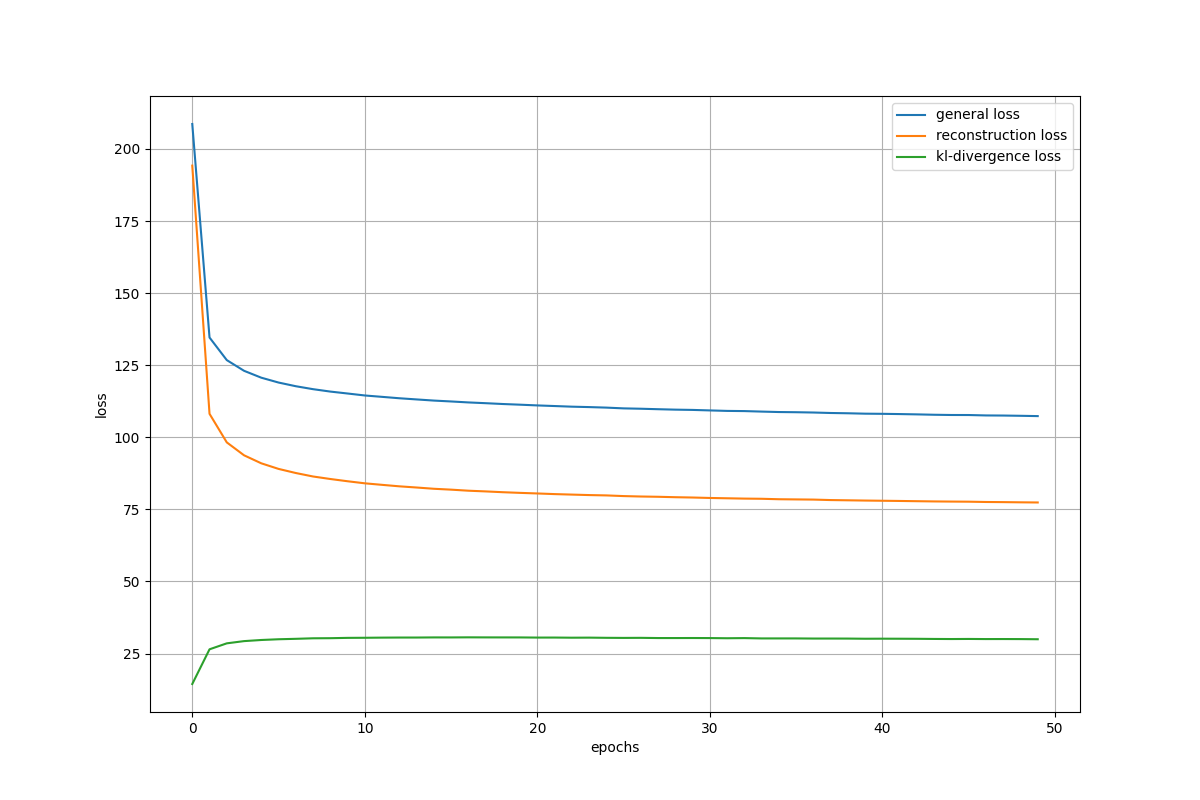
Training Loss – Deeper Decoder
🔹 Dropout Integration
Setup: Dropout layers added to improve generalization.
Observations:
- Training loss curves became unstable.
- Generated images showed incomplete or noisy digits.
- Dropout alone did not improve diversity.
🔹 Optimized Configuration
Setup: Smaller dense layers, increased convolution channels, learning rate increased to 0.001.
Observations:
- Reconstructions were consistent and clear.
- Generated samples covered digits 0–9.
- Convergence was faster.
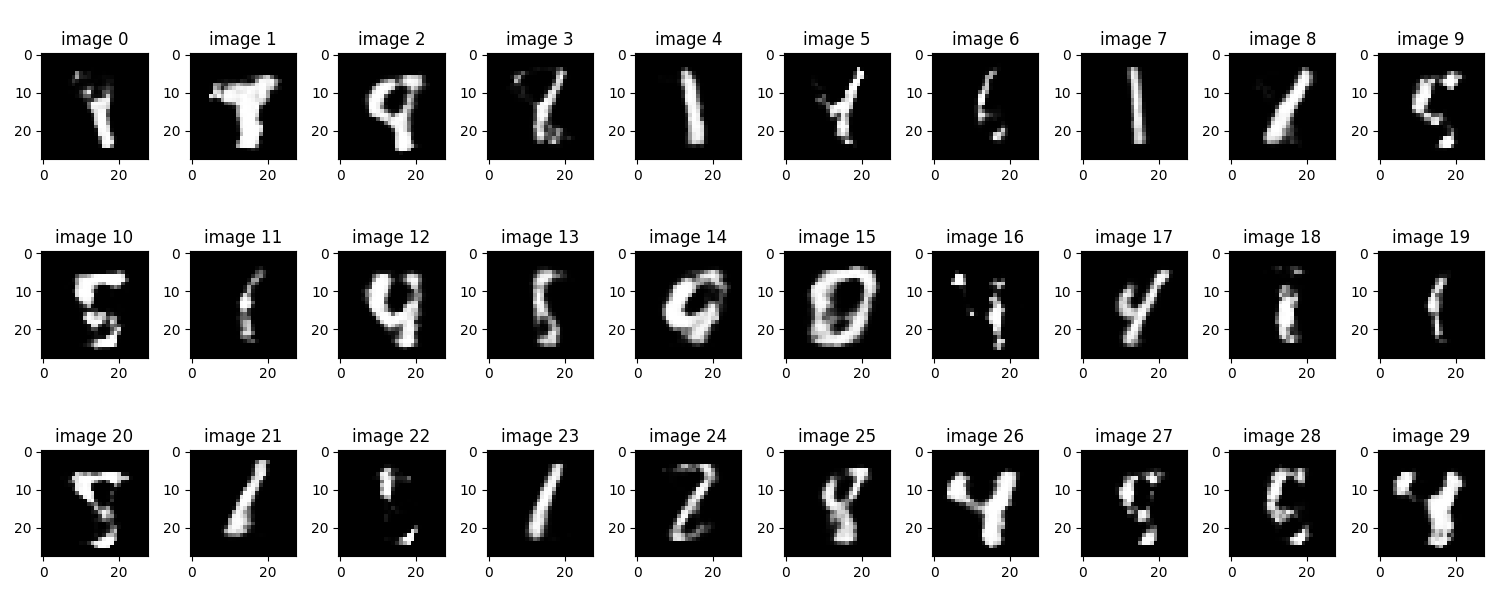
Reconstructions – Optimized Model
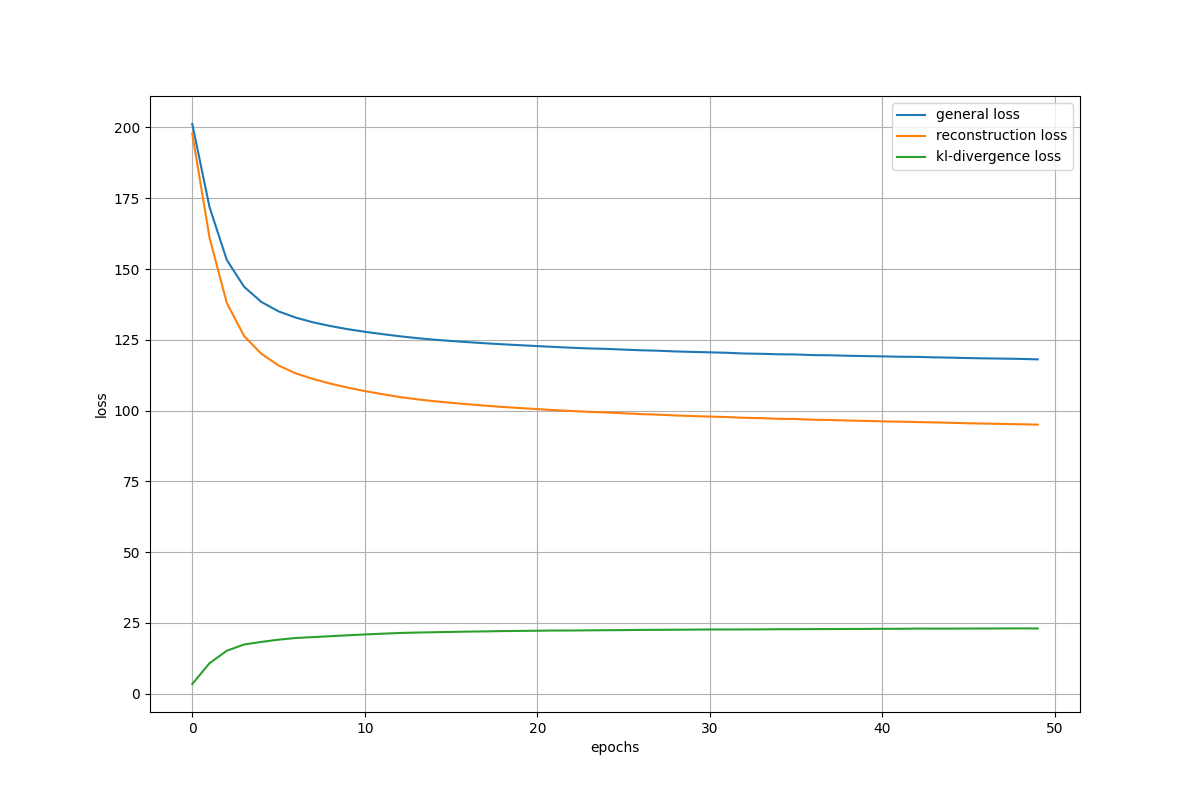
Training Loss – Optimized Model
🔹 Generated Samples
Sampling from latent space demonstrated improvement over experiments.

Generated Samples – Early Model

Generated Samples – Refined Settings

Generated Samples – Random Latent Vectors
📝 Reflections
- The LSTM encoder improved sequential feature extraction compared to simple dense encoders.
- Learning rate adjustments significantly affected convergence speed and reconstruction stability.
- KL divergence helped maintain latent space regularity, supporting smooth interpolation.
- Excessive dropout reduced output quality.
- Overall, combining sequence modeling and convolutional decoding yielded diverse generative outputs.
⚙️ Technical Stack
- Language: Python
- Libraries: TensorFlow, Keras, NumPy, Matplotlib
- Dataset: MNIST handwritten digits