Attention-Based Knowledge Distillation for HAR
Lightweight human activity recognition (HAR) combining knowledge distillation and attention modules to improve performance on wearable sensor data
✨ Motivation
Deploying Human Activity Recognition (HAR) models on wearables requires balancing accuracy and efficiency. Large deep networks can achieve high performance, but they are impractical for resource-constrained devices. This project explores how combining knowledge distillation and attention mechanisms can train compact models that retain competitive recognition accuracy with dramatically reduced computation and model size.
🧭 Approach Overview
The work compares several configurations:
- LM (Lightweight Model): A compact student network trained from scratch.
- RB-KD (Response-Based Knowledge Distillation): The student trained to match the softened predictions of a larger teacher model.
- LM-Att: Adding channel and spatial attention to the lightweight model.
- RB-KD-Att: RB-KD with attention modules in the student.
- RAB-KD (Response and Attention-Based KD): The most advanced variant, where the student mimics both predictions and attention maps from the teacher.
🧮 Loss Formulations
Student Prediction Loss (Cross-Entropy):
\[L_{\text{stud}} = - \sum_{k} y_k \log(p_k)\]Distillation Loss (KL Divergence):
\[L_{\text{dist}} = \sum_{k} q_k^{(T)} \log \frac{q_k^{(T)}}{q_k^{(S)}}\]Channel Attention Loss:
\[L_{CA} = \frac{1}{C} \sum_{c=1}^C \bigl(M_c^{(T)} - M_c^{(S)}\bigr)^2\]Spatial Attention Loss:
\[L_{SA} = \frac{1}{H \times W} \sum_{i=1}^H \sum_{j=1}^W \bigl(M_{s,ij}^{(T)} - M_{s,ij}^{(S)}\bigr)^2\]Total Attention Loss:
\[L_{\text{Att}} = L_{CA} + L_{SA}\]Overall Objective:
\[L = \alpha \cdot L_{\text{stud}} + (1-\alpha) \cdot L_{\text{dist}} + \beta \cdot L_{\text{Att}}\]📘 CBAM Attention Mechanism
The channel and spatial attention modules were adapted from the Convolutional Block Attention Module (CBAM):
Channel Attention:
\[M_c(F) = \sigma\bigl(\text{MLP}(\text{AvgPool}(F)) \oplus \text{MLP}(\text{MaxPool}(F))\bigr)\]Spatial Attention:
\[M_s(F) = \sigma\Bigl(f^{7 \times 7}\bigl[\text{AvgPool}(F)\ ;\ \text{MaxPool}(F)\bigr]\Bigr)\]Feature Refinement:
\[F' = M_c(F)\ \otimes\ F\] \[F'' = M_s(F')\ \otimes\ F'\]where \(\oplus\) denotes elementwise summation and \(\otimes\) denotes elementwise multiplication.
🛠️ Experimental Setup
- Datasets: Opportunity, WISDM, UCI Sensors
- Sensors: Wrist accelerometer and gyroscope
- Metrics: F1-Score, Accuracy, FLOPs, Model size
- Training: Adam optimizer with temperature scaling for softened outputs
Baseline Performances per Dataset (Without attention, without distillation):
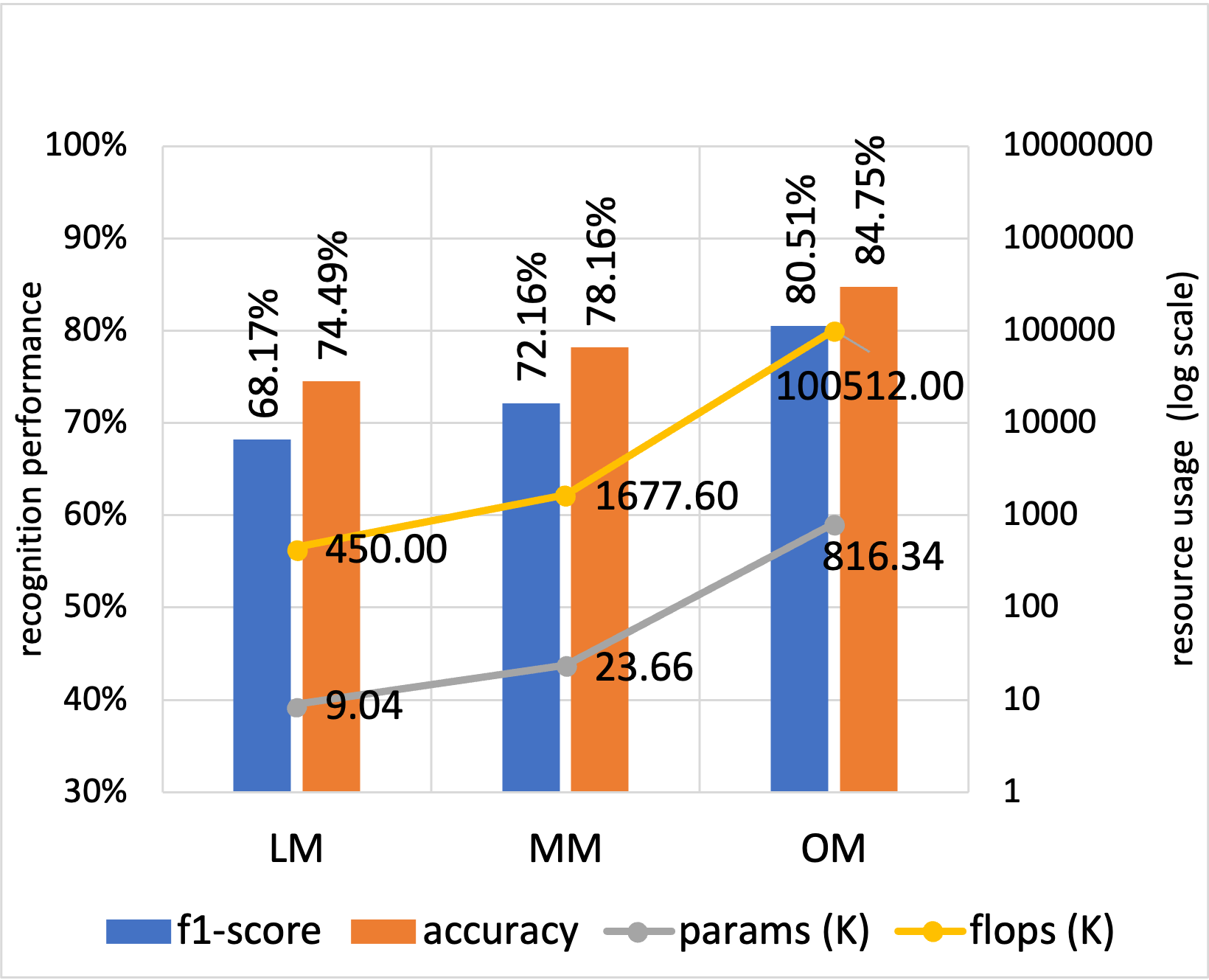
Opportunity dataset
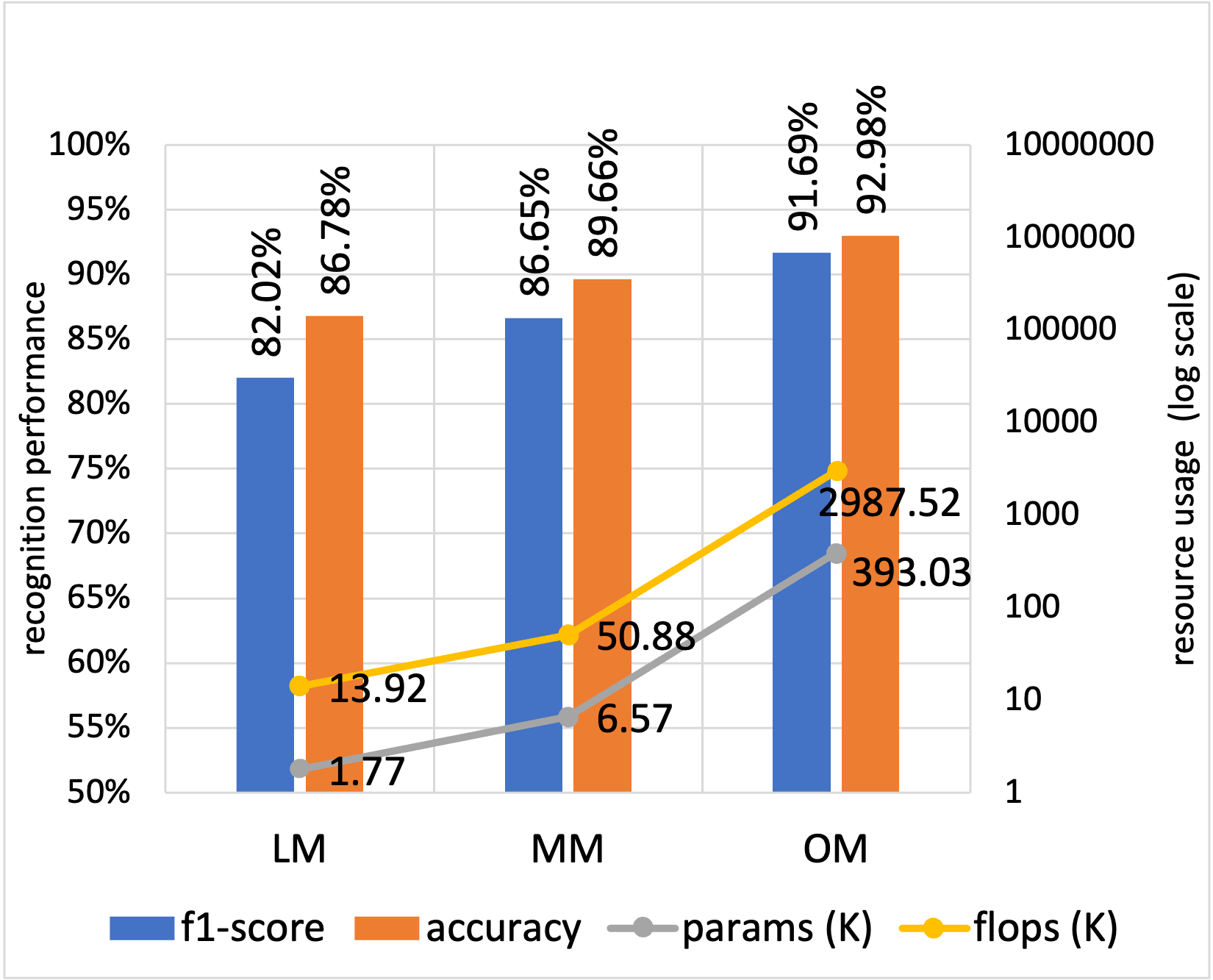
WISDM dataset
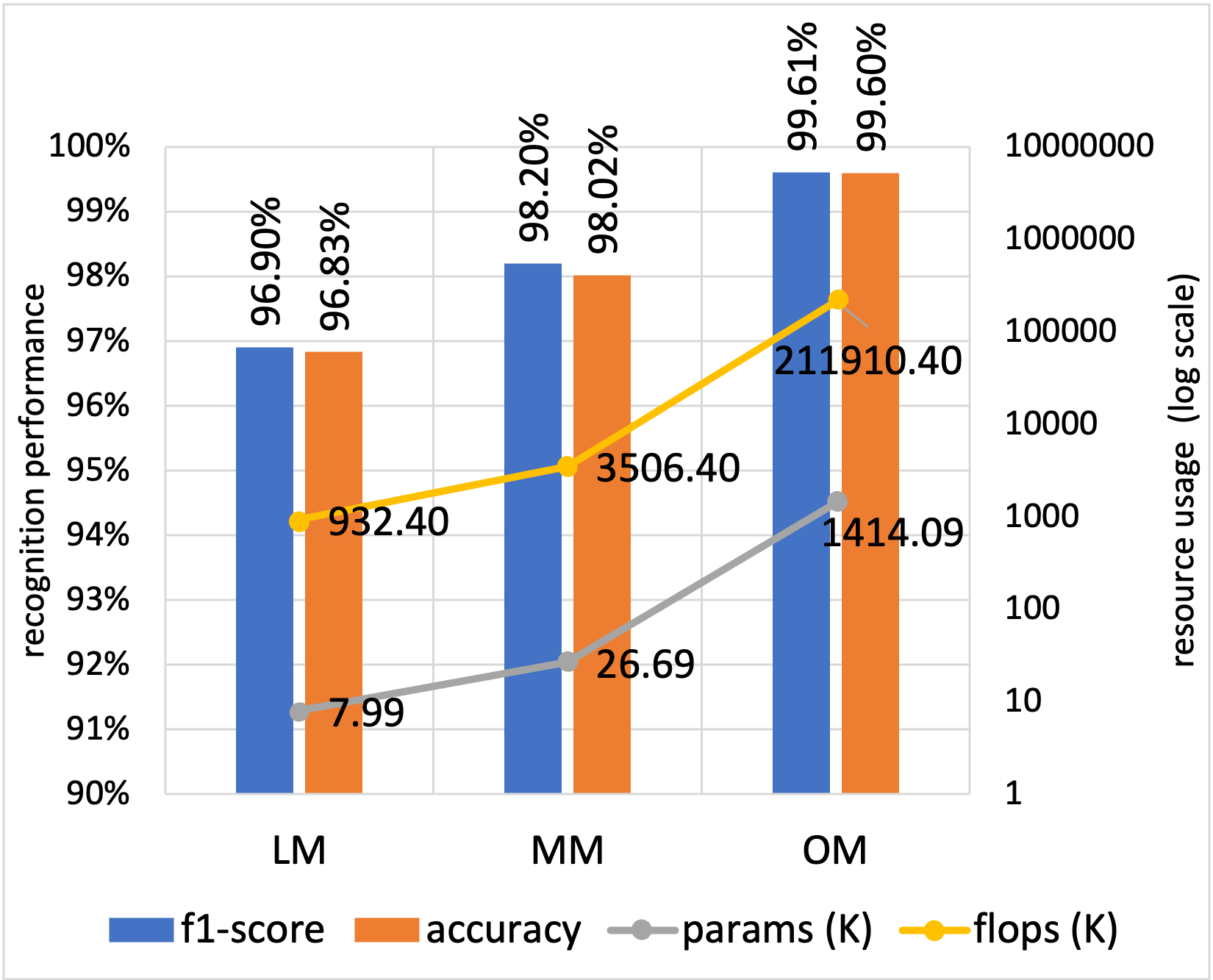
UCI Sensors dataset
📊 Evaluation Results
Model Size per Dataset:
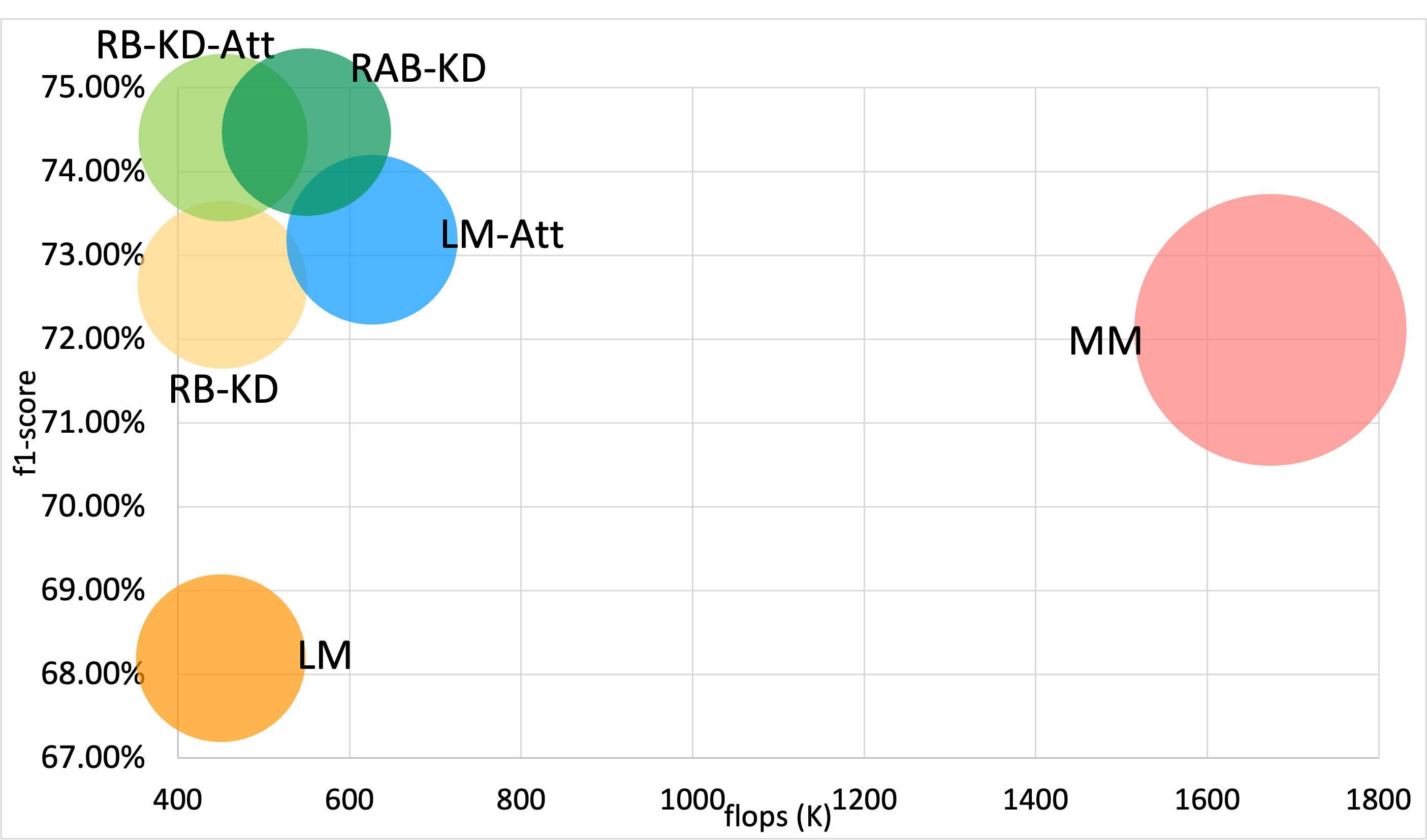
Opportunity dataset
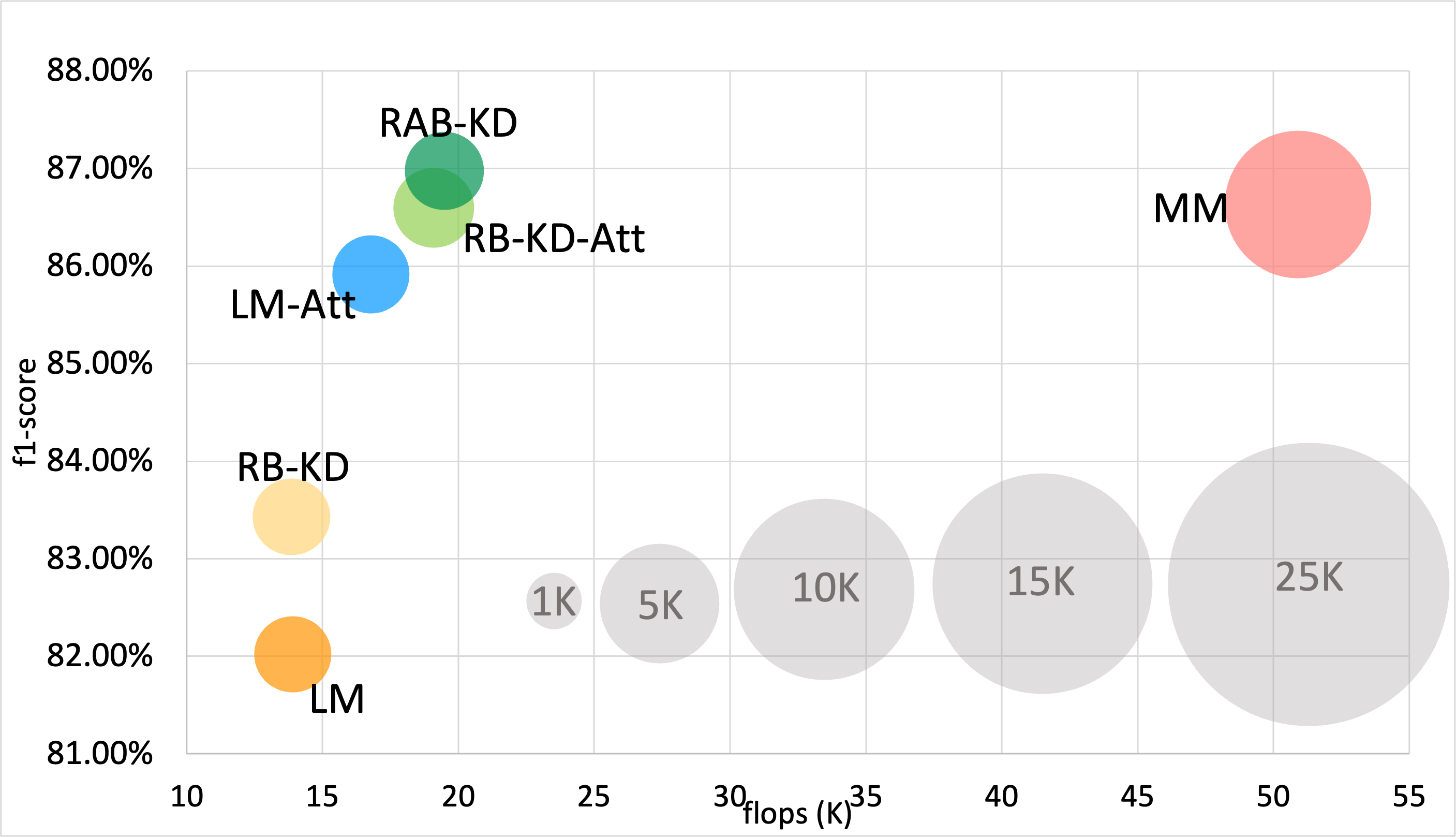
WISDM dataset
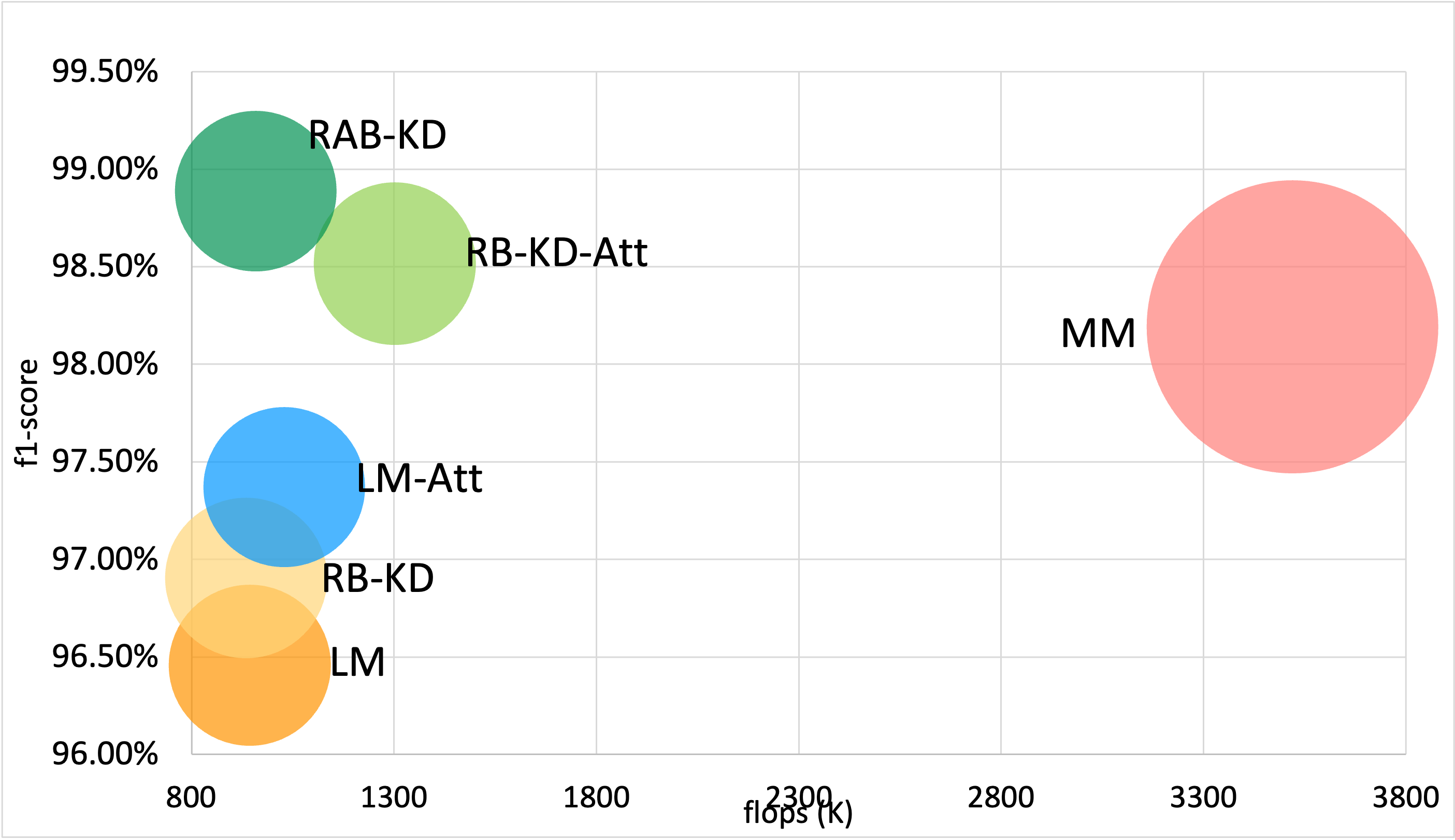
UCI Sensors dataset
Recognition Success and Resource Usage Comparison:
In the figures below, the y-axis shows relative values normalized with respect to the LM baseline. The LM values are denoted in the orange boxes within each chart for reference.
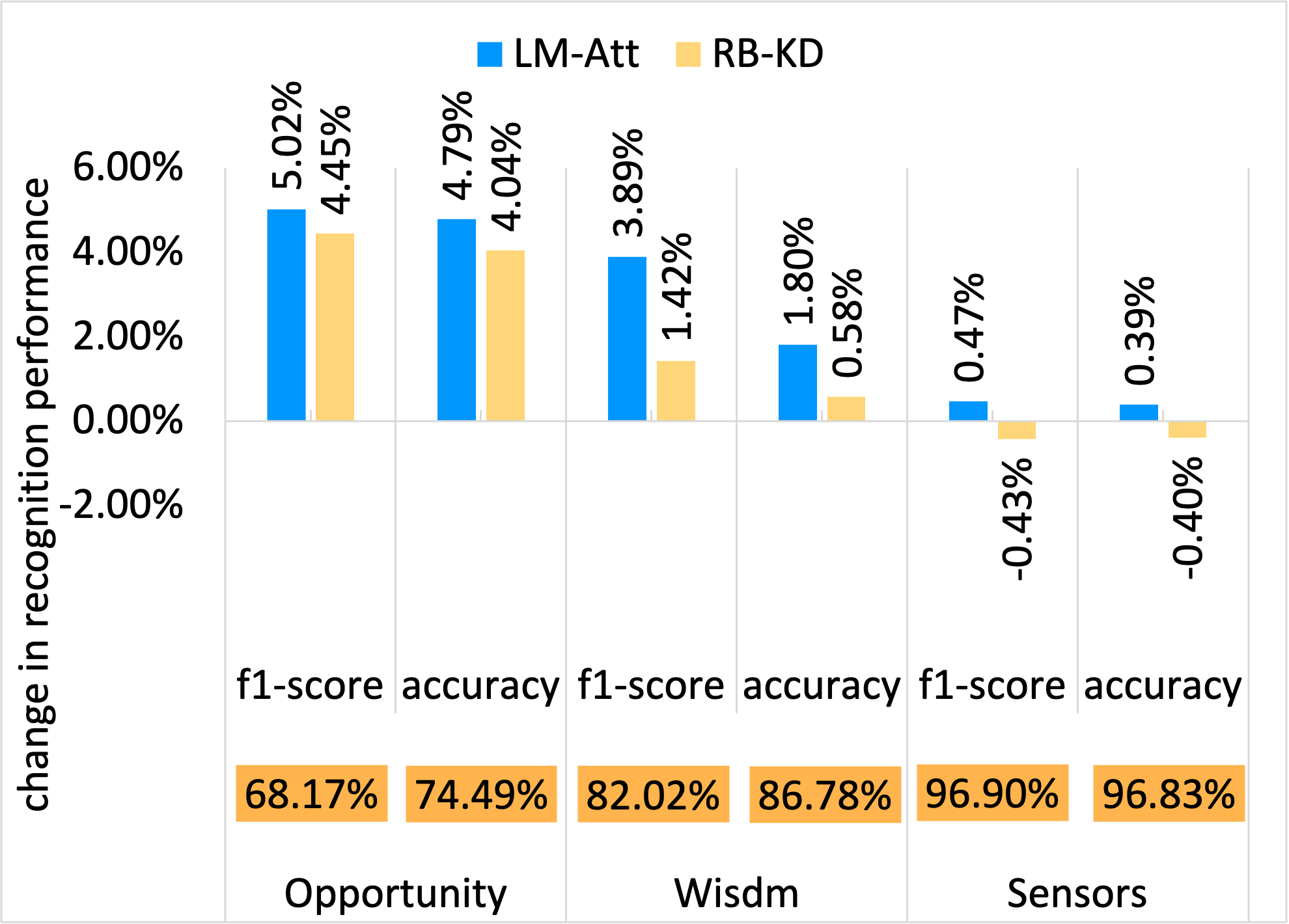
Opportunity dataset - Recognition success
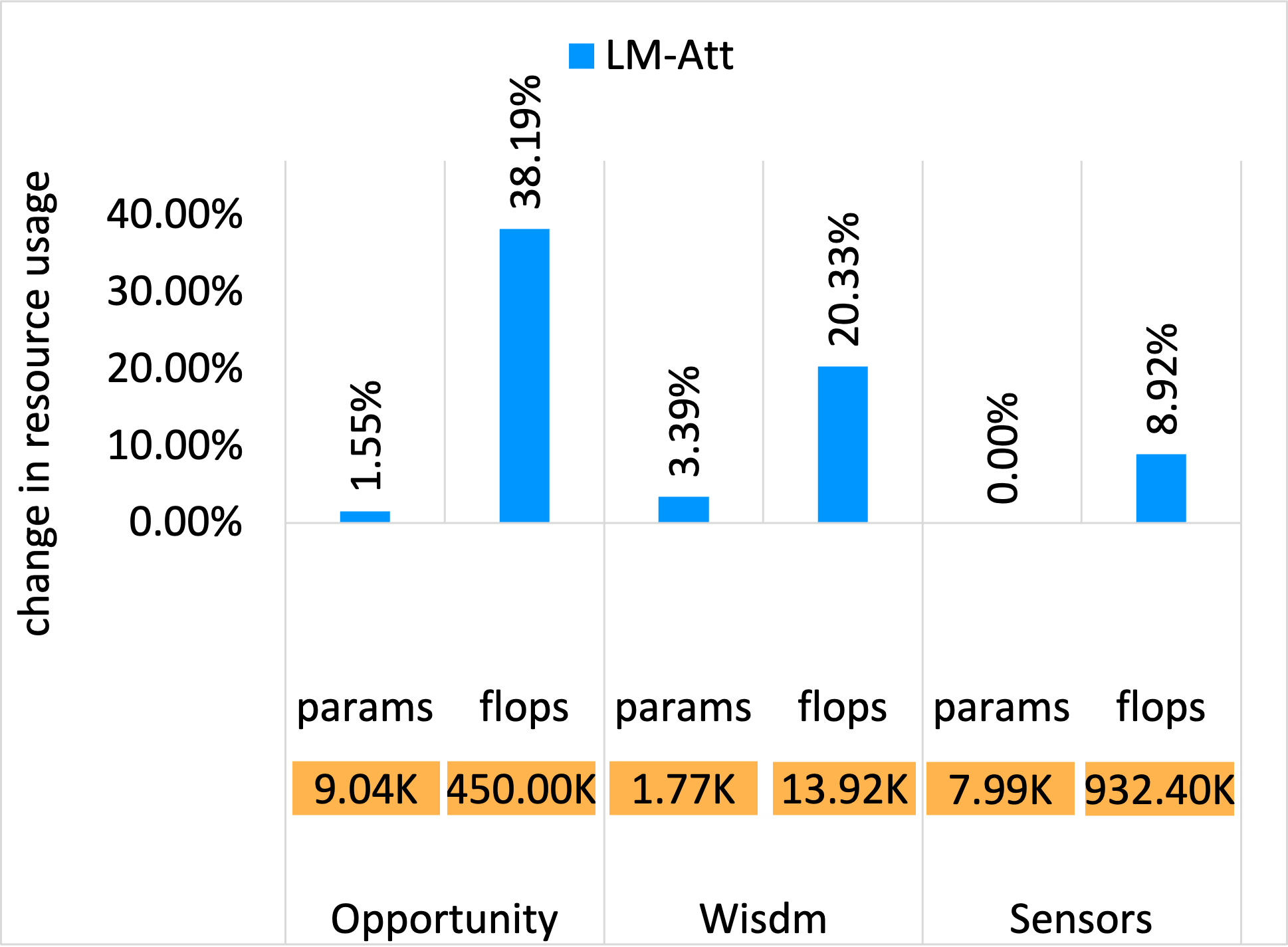
Opportunity dataset - Resource usage
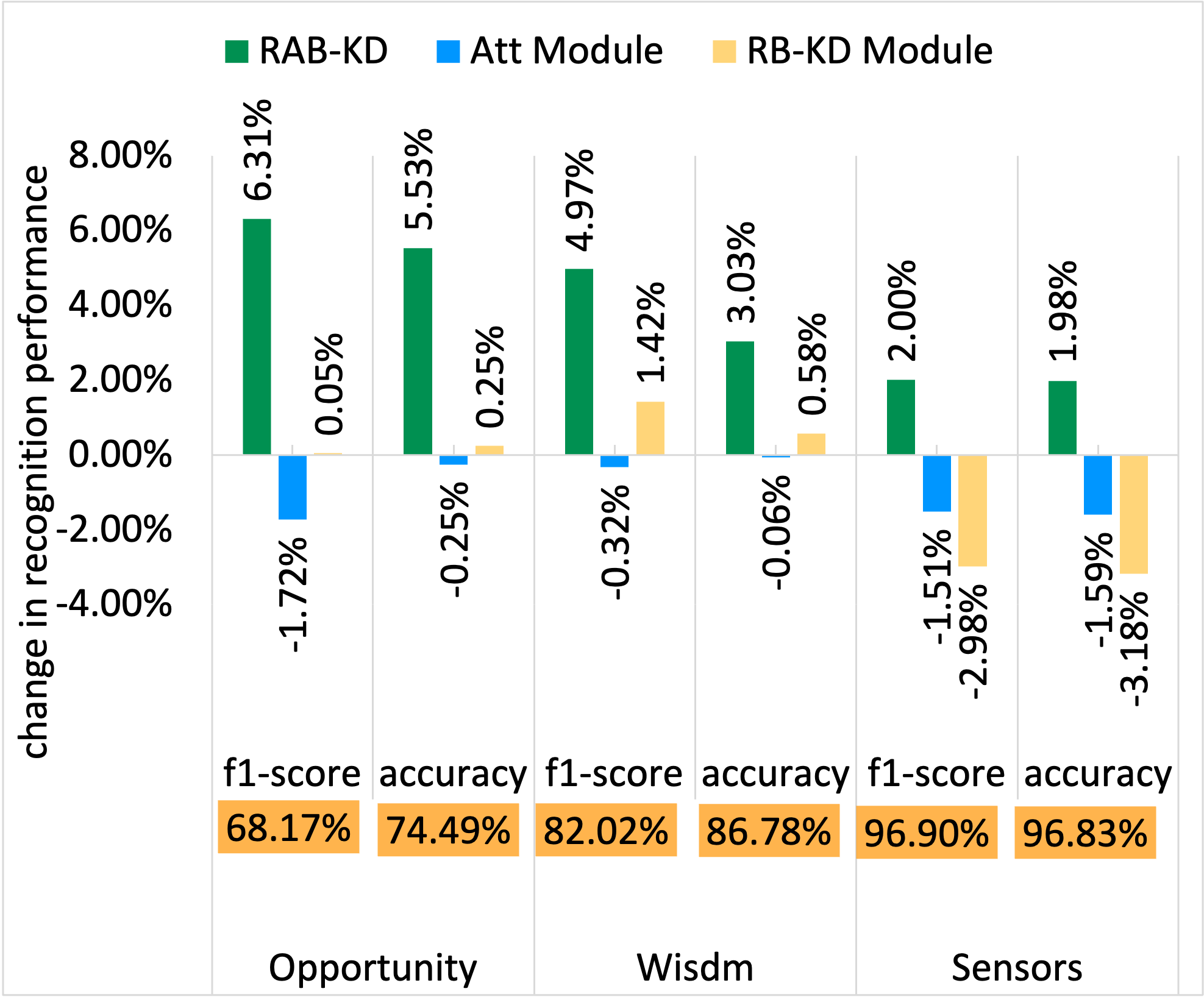
WISDM dataset - Recognition success
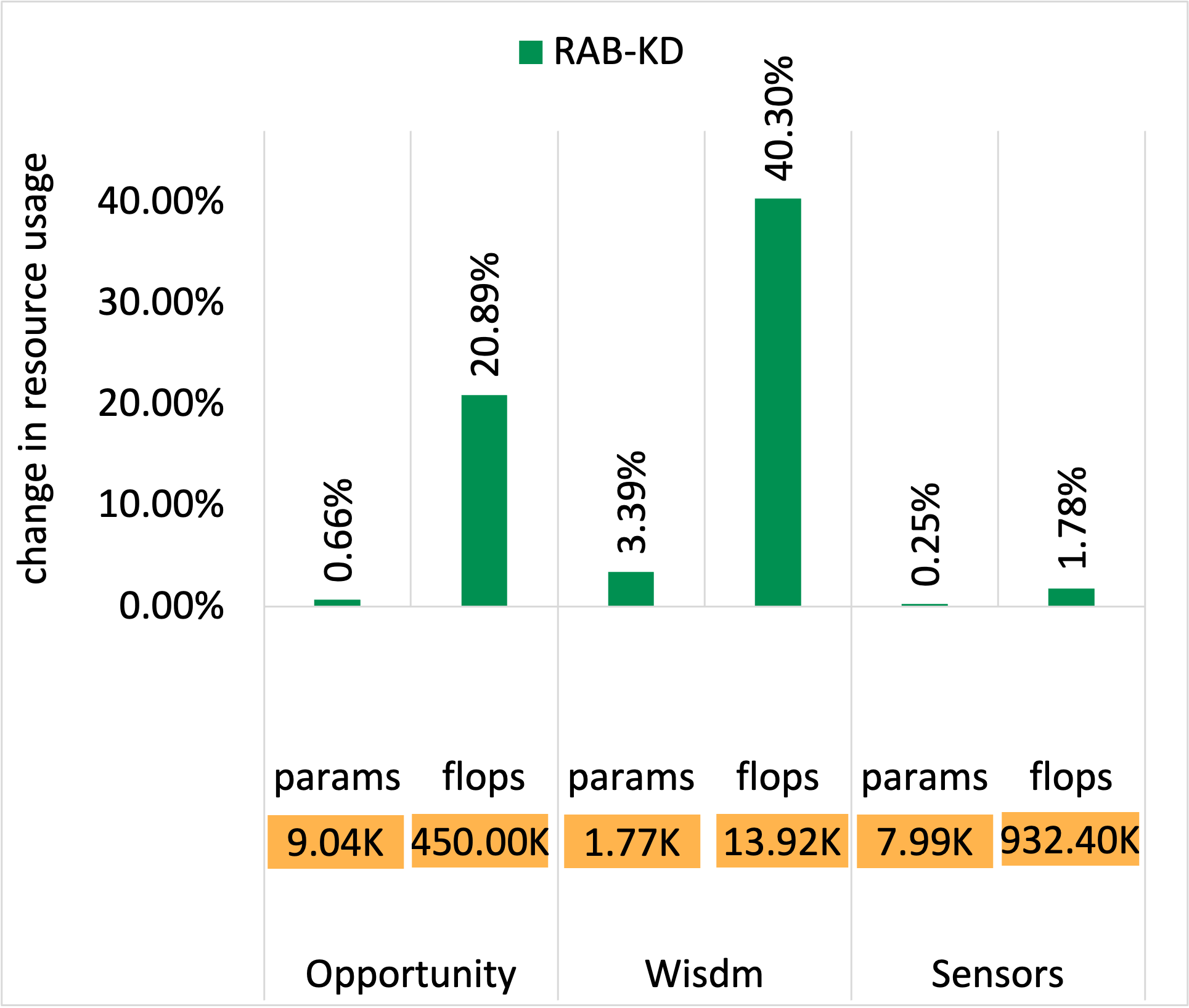
WISDM dataset - Resource usage
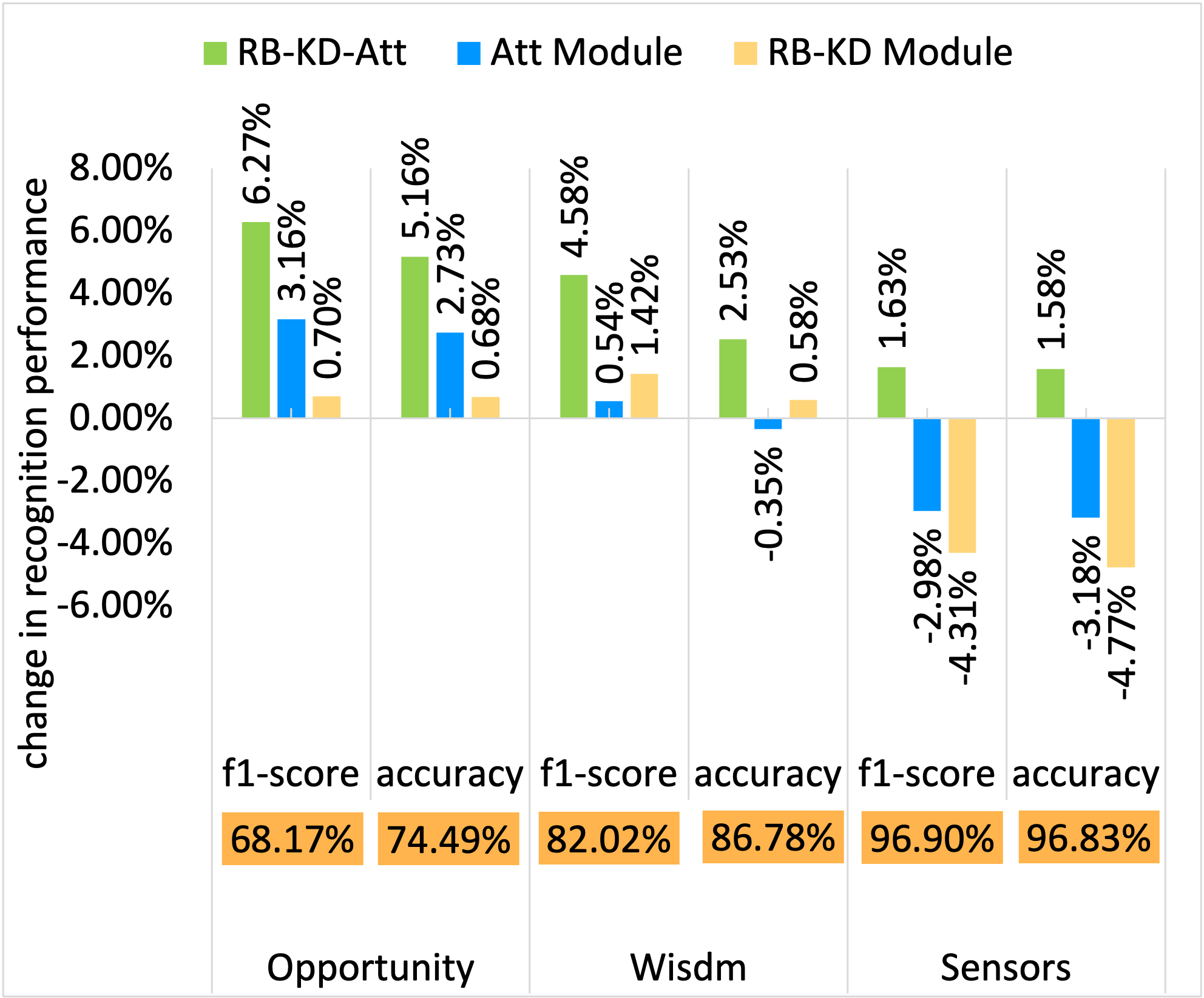
UCI Sensors dataset - Recognition success
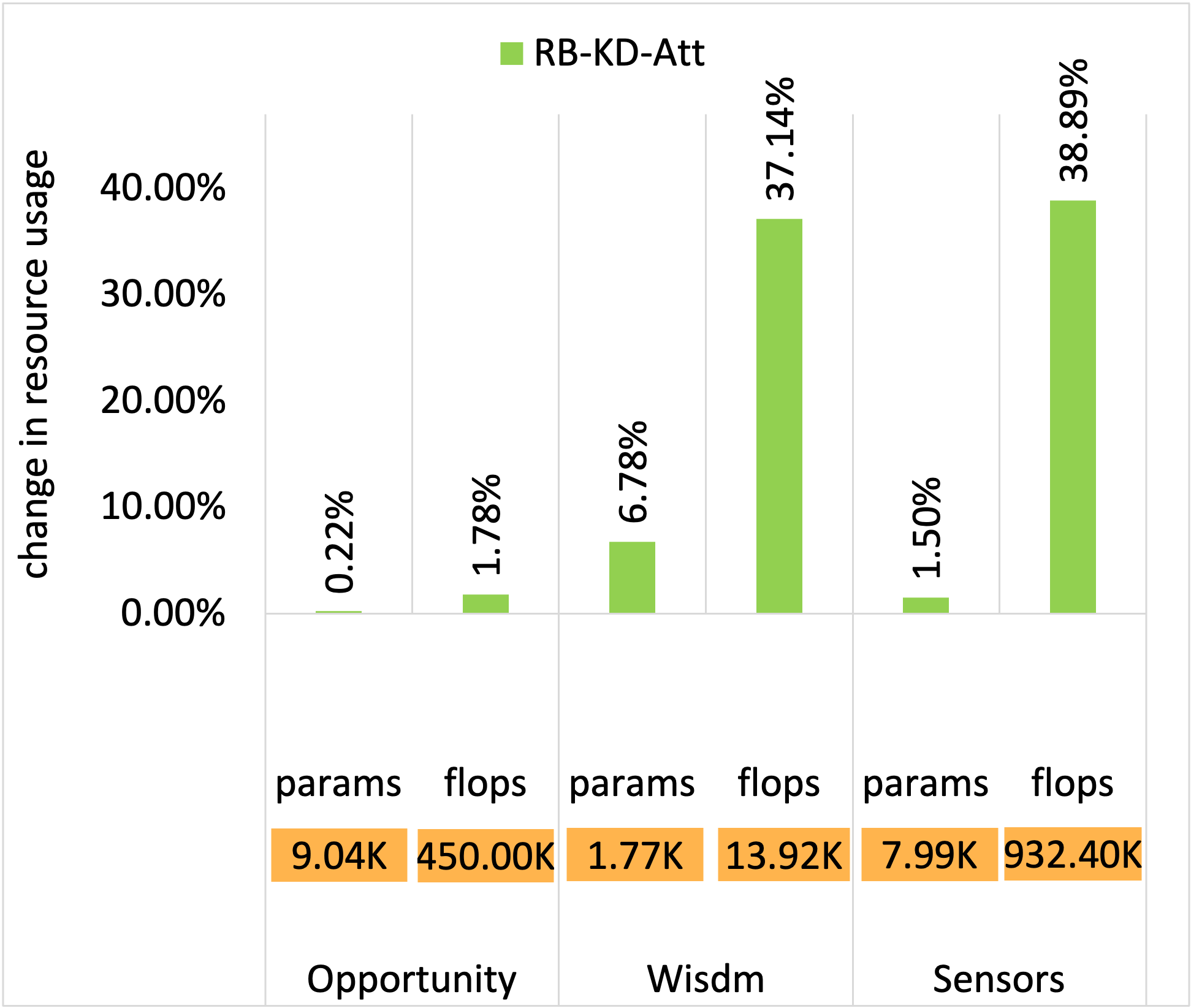
UCI Sensors dataset - Resource usage
📝 Key Takeaways
- Knowledge distillation alone improved F1-score by 4–6% compared to training the lightweight student model from scratch, confirming the benefit of mimicking softened teacher outputs.
- Adding CBAM-based channel and spatial attention modules further increased F1-score by 3–5%, especially on Opportunity and WISDM datasets where activity patterns are more complex.
- The RAB-KD configuration achieved the highest overall accuracy, reaching up to 82% F1-score, while reducing FLOPs by approximately 8–10× compared to the teacher model.
- Across all datasets, attention distillation models increased parameter count by only 10–15% relative to the base LM, demonstrating a favorable trade-off between performance and resource footprint.
- These results highlight that combining response-based and attention-based distillation enables accurate, efficient, and deployable HAR models suitable for real-time operation on wearable platforms.
⚙️ Technical Stack
- Language: Python
- Libraries: TensorFlow, Keras, NumPy
- Datasets: Opportunity, WISDM, UCI Sensors
- Hardware: GPU-enabled compute node